前言
说到文生图,可能有些人不清楚,但要说 AI 绘画,就有很多人直呼:

2022 可以说是 AI 绘图大爆发的元年。
AI 绘画模型可以分为扩散模型(Diffusion Model)、自回归模型(变分自编码器,Autoregressive Model)、生成对抗网络模型(GAN,Generative Adversarial Networks)三大路径。
扩散模型有代表的例如 Midjorney,Stable Diffusion、DALL-E 2,自回归模型以 DALL-E、parti 等代表,GAN 例如有 StackGAN++等。
扩散模型(大家还可以看看 huggingface 的 diffusers 库,收集了很多 Diffusion model)由于生成图像质量高(FID 值小),开源等特点,成为当下技术的主流。
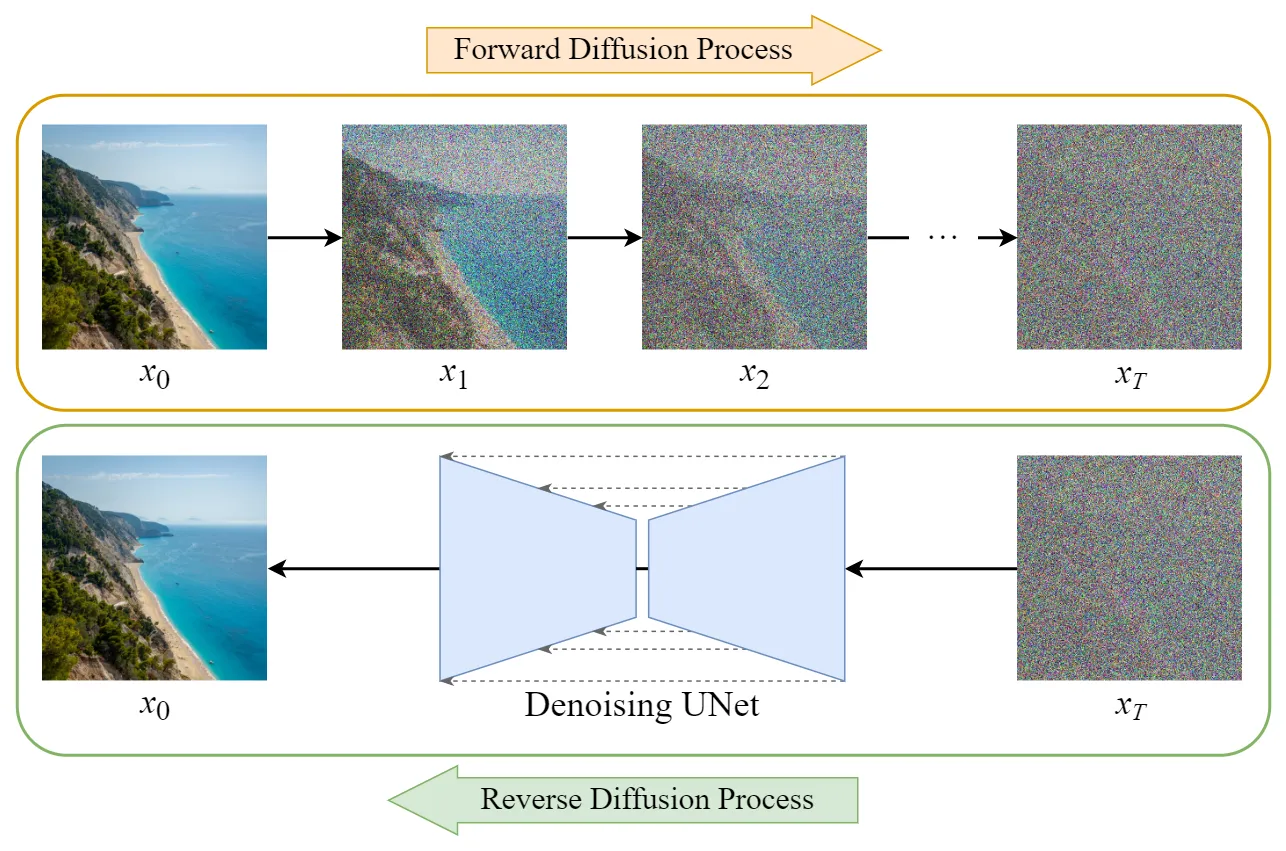
发展
那么 2023 年,文生图领域卷到哪里了呢?
提前说明一下:
- 这里只说模型架构,不谈应用,当然如果是没技术细节没论文我也随便说下,因为不保真,不知道是不是你真自研 🥲。
- 不同于别人写的流水账,我不仅介绍发展,还会粗略地介绍技术,进行简单的抛砖引玉,希望能够激起大家的兴趣,不断学习,多看相关知识,看一篇是不能完全理解原理的。
好的,废话不多说,现在开始。
1 月
23 年 1 月左右,微软在 21 年发表的LoRA能够极少数据微调模型,瞬间在 AI 绘图中火起来,这是目前最流行的微调 SD 的方法之一。
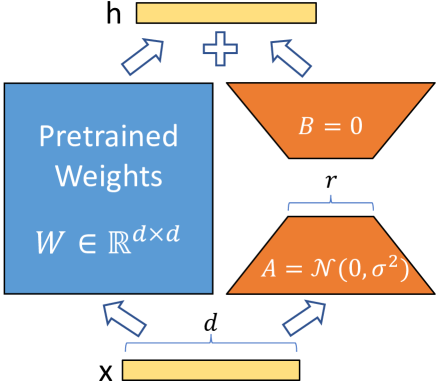
LoRA 的示意图如上,对于预训练的权重矩阵,LoRA 增加了 A 和 B 这两个低秩矩阵,其中 A 是采用高斯初始化,B 的初始值是 0,在训练时只更新 A、B 的参数,w 被冻结,公式如下:。称为微调权重,是个超参数,r 是矩阵的秩。
其实这个原理,你可以认为,本来的预训练权重很大,这时候被冻结了,我们反而学习新的知识,但这个知识的大小是精华,量小而有效,我们就靠它来微调我们的模型,节省训练的代价。
17 日,GLIGEN 模型由威斯康星大学麦迪逊分校、哥伦比亚大学和微软的研究人员和工程师创建。该方法能够在现有的预训练好的扩散模型的基础上,增加对定位输入的支持,从而实现开放集的基于定位语言的图像生成。
23 日,来自英伟达等机构的研究者死活不服扩散模型如今地地位,试图表明 GAN 仍然具有竞争力,提出StyleGAN-T模型,只需 0.1 秒即可生成 512×512 分辨率图像。
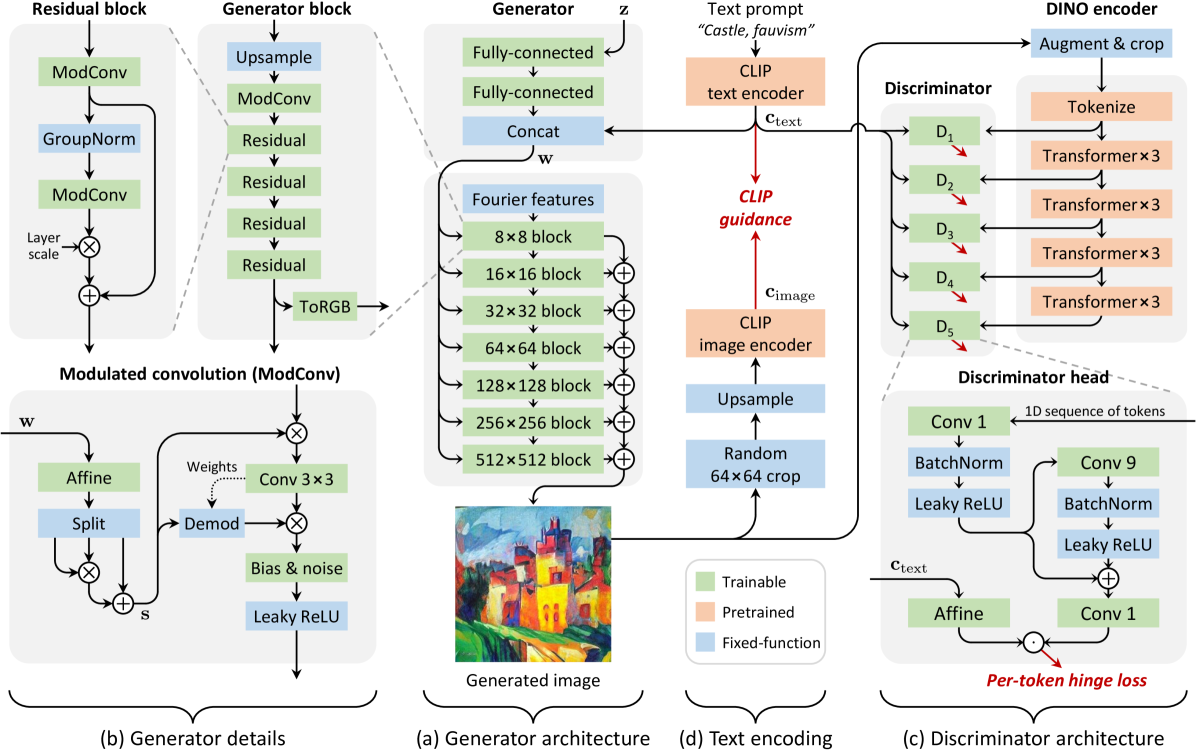
该研究选择 StyleGAN-XL 作为基线架构,因为 StyleGAN-XL 在以类别为条件的 ImageNet 合成任务中表现出色。然后该研究依次从生成器、判别器和变长与文本对齐的权衡机制的角度修改 StyleGAN-XL。作者使用零样本 MS COCO 来衡量改动的效果,使用预训练的 CLIP ViT-L/14 文本编码器来嵌入文本提示,以此来代替类别嵌入,删除了用于引导生成的分类器。
2 月
9 日,UniPC是 23 年提出的调度器,受到同名的常微分方程求解法思路的影响。可以在 5-10 个步骤中实现高质量图像生成。
10 日,张吕敏发布了ControlNet,那么什么是 ControlNet 呢?
我还记得在高铁上,突然刷到 ControlNet(量子位发表的“四少女火爆外网...”),用户终于可以控制图片生成的稳定性,ControlNet 的核心思想是在文本描述之外添加一些额外条件来控制扩散模型(如 Stable Diffusion),从而更好地控制生成图像的人物姿态、深度、画面结构等信息。
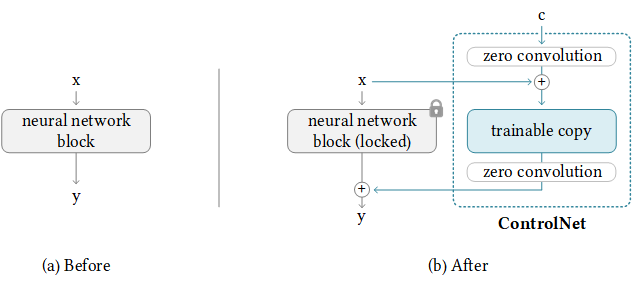
我们可以看到使用 controNet,它将神经网络块的权重复制为“locked”副本和“trainable 可训练”副本。zero convolution是权重和偏差都初始化为零的 1×1 卷积。最后还会把零卷积后的可训练副本和冻结副本相加。
这样的好处是,锁定副本保留了原来模型能力,最后把训练出来的新知识进行相加,使得模型训练时候不会忘记自己今天来月球是来干什么的,哦,原来只要跨一小步就行了。零卷积会在训练中,逐渐成为具有非零权重的公共卷积层,并不断优化参数权重。
16 日,腾讯提出T2I-Adapter,*“挖掘”T2I 模型隐式学习的能力,然后显式地使用它们来更精细地控制生成。*学习简单且轻量级的 T2I 适配器,以将 T2I 模型中的内部知识与外部控制信号结合起来,同时冻结原始的大型 T2I 模型。
23 日,谷歌提出一种通过人类反馈来改进文生图模型的图文一致性的方法,仅使用基于Reward的加权损失对文本到图像模型进行微调。
3 月
2 日,OpenAI 提出了Consistency Models,它是一种支持快速 one-step 生成的模型,并且仍然允许 few-step 采样,以在计算量和样本质量之间做出权衡。它们还支持零样本数据编辑,例如图像修复、着色和超分辨率,而无需为这些任务进行具体训练。Consistency Models 可以通过蒸馏预训练扩散模型的方式进行训练,也可以作为独立的生成模型进行训练。
9 日,针对增加 StyleGAN 架构容量会导致不稳定的问题,来自浦项科技大学(韩国)、卡内基梅隆大学和 Adobe 研究院的研究人员提出了一种全新的生成对抗网络架构GigaGAN,打破了模型的规模限制,展示了 GAN 仍然可以胜任文本到图像合成模型。
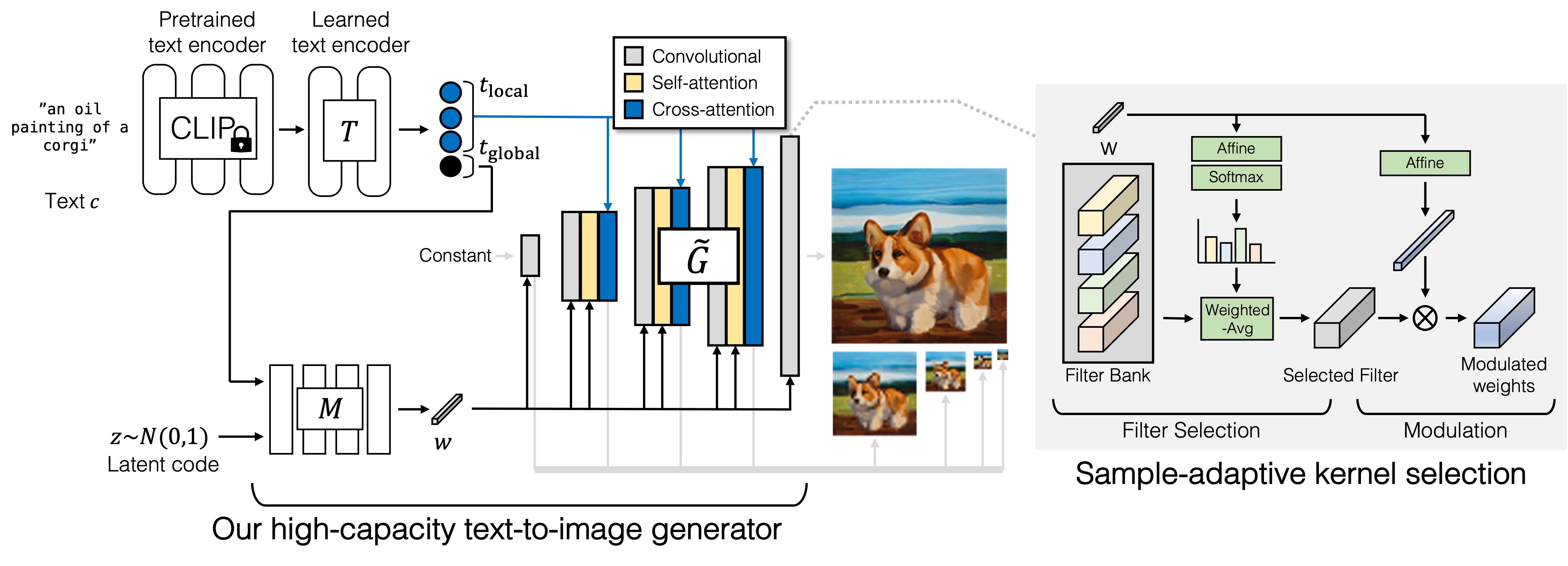
GigaGAN 生成器是由文本编码分支、风格映射网络、多尺度合成网络组成,并通过稳定注意力和自适应内核选择进行增强。在文本编码分支中,首先使用预训练的 CLIP 模型和学习的注意力层 T 来提取文本嵌入。然后将嵌入传递到样式映射网络 M,以生成样式向量 w,类似于 StyleGAN。合成网络使用样式代码作为调制,使用文本嵌入作为注意力来生成图像金字塔。此外,引入样本自适应内核选择,根据输入文本条件自适应地选择卷积内核。
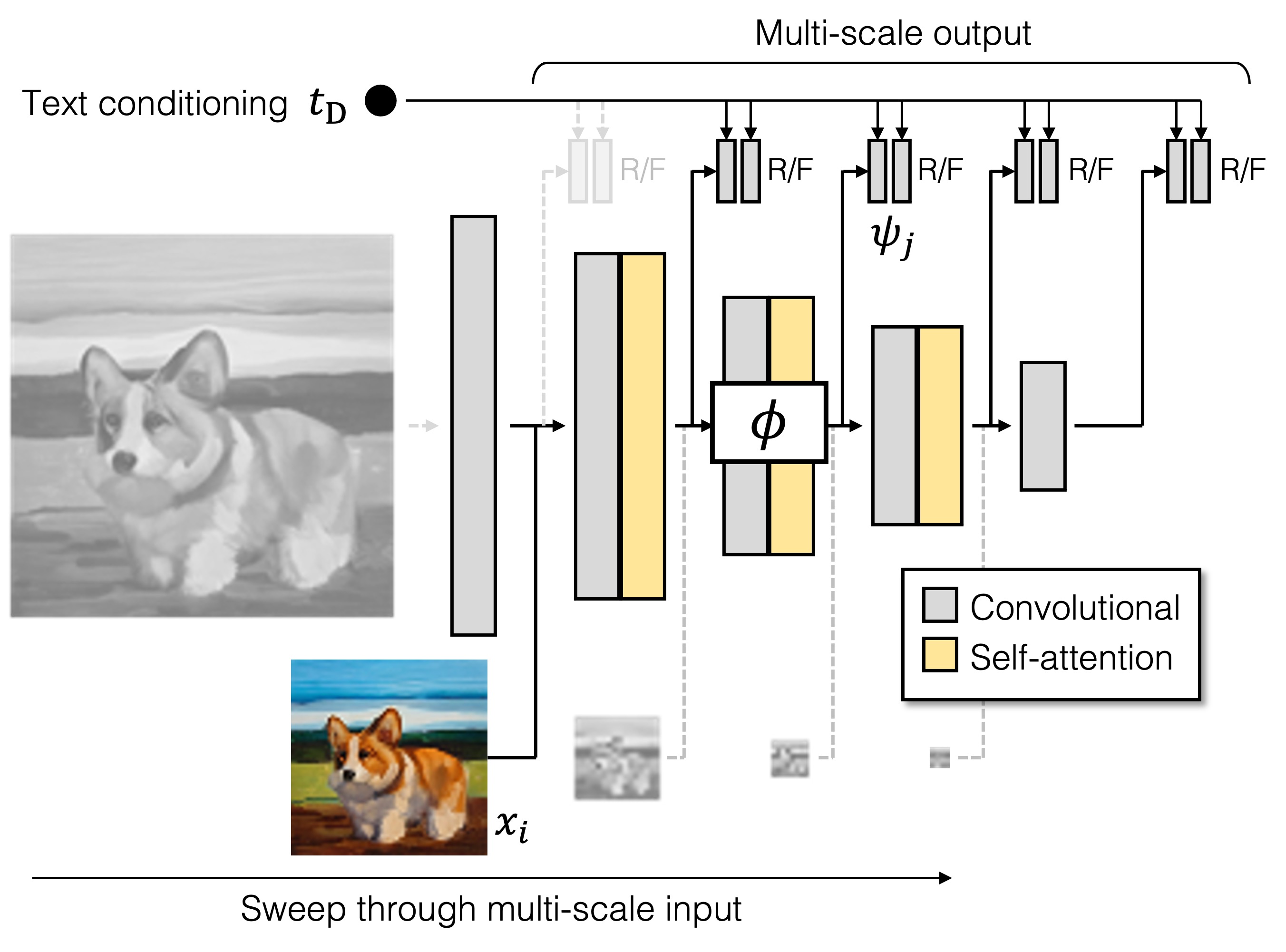
判别器由两个分支组成,一个处理图像条件,一个处理文本条件。图像分支接收图像金字塔并对每个图像尺度进行独立预测,并在下采样层的所有后续尺度上进行预测。此外,采用额外的损失来鼓励有效的收敛。
结果是比 SD1.5 更快,图像质量更好。
21 日,Adobe 发布了 Firefly(萤火虫),在 6 月,ps 也能玩 AI 辅助了。由于是设计公司发布的,所以其输出的内容可以分层、精细化地进行修改,一切为了设计。由于是设计公司,真的一点细节都没有,真的论文也不露一手。所以我也不给你配图了!
4 月
21 日,谷歌实现了在 GPU 驱动的设备上运行 Stable Diffusion 1.4 ,达到 SOTA 推理延迟性能(在三星 S23 Ultra 上,通过 20 次迭代生成 512 × 512 的图像仅需 11.5 秒)。论文地址,此前,有研究者开发了一个应用程序,该应用在 iPhone 14 Pro 上使用 Stable Diffusion 生成图片仅需一分钟,使用大约 2GiB 的应用内存。谷歌为Group Norm 和 GELU设计了专用内核,优化 softmax,提高注意力模块的效率,并且使用Winograd 卷积,Stable Diffusion 的主干在很大程度上依赖于 3×3 卷积层,于是使用 4x4 tile 大小的 Winograd 进行优化。
23 日,俄罗斯团队发布了 Kandinsky2.1,这是继承了 Dall-E 2 和潜在扩散的最佳实践,同时引入了一些新的想法。作为文本和图像编码器,它使用 CLIP 模型和 CLIP 模式的潜在空间之间的扩散图像先验(映射)。这种方法提高了模型的视觉性能,并揭示了混合图像和文本引导图像操作的新视野。
5 月

9 日,面对当前预训练的扩散模型在处理简单叙述提示时,理解语义和进行常识推理方面存在限制,这会导致图像生成效果不理想的现状,国内中山大学 HCP 实验室提出了SUR-adapter,一种简单而有效的参数高效微调方法。
他们引入了一个新数据集叫做 SURD,它包含超过 57,000 个经过语义修正的图像和文本对。此外,他们还开发了一个名为 SUR 适配器的模块,该模块能够从基于关键字的复杂提示和大型语言模型中提取语义理解和推理知识。通过对 SURD 进行大量实验和严格评估,结果表明 SUR 适配器能够增强扩散模型的语义理解能力,同时不影响图像生成的质量。
12 日,清华提出了UniDiffuser,采用称为U-ViT 的 transformer 主干,这也是首个基于 Transformer 的多模态扩散大模型,率先发布了对多模态生成式模型的一些探索工作,实现了任意模态之间的相互转化。除了单向的文生图,还能实现图生文、图文联合生成、无条件图文生成、图文改写等多种功能,大幅提升文图内容的生产效率,也进一步提升了生成式模型的应用想象力。
众所周知,Diffusion 耗时最长的是 Unet 结构,所以天下苦卷积久矣,当它出来的时候,好家伙,研究了几年的 Transformer,什么又回卷积了。
将 diffusion unet 换成 transformer,这是我目前看到的第二篇,还有一篇是 22 年 12 月 20 提出的[Scalable Diffusion Models with Transformers,这是我目前看到的首个将 UNet 架构换成 transformer(DIT),但是实践下来,提示词太限制了...效果没有 U-ViT 好。
17 日,MIT 提出了FastComposer是一种无需微调、个性化、多主题的文本到图像生成方法,它利用图像编码器提取的主题嵌入来增强扩散模型中的文本条件,在生成图像身份保持方面优于 Stable Diffusion、Custom Diffusion、DreamBooth 等。
24 日,Salesforce 公司开源了自己最新的文生图的研究成果:Blip-diffusion,源码 1,源码 2,通过BLIP-2 编码器来提取多模态主题表示,然后将其与文本提示一起用于扩散模型引导,使得生成图像既能捕获特定主题的视觉外观特征,又能很好地与文本提示对齐。
29 日,商汤提出的绘画大模型RAPHAEL,也是基于扩散模型开发。
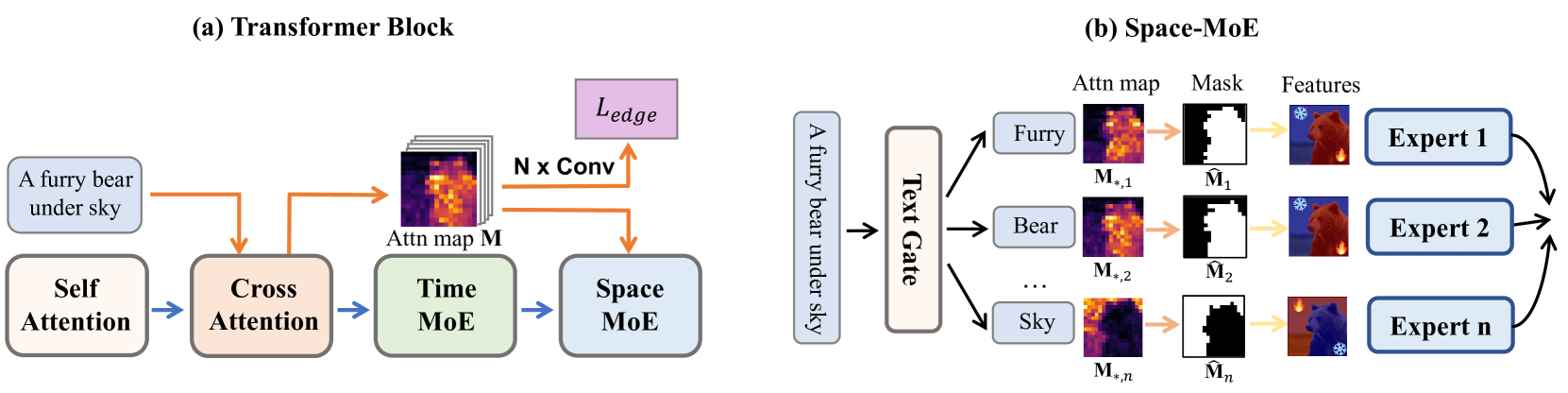
(a) 每个块包含四个主要组件,包括自注意力层、交叉注意力层、空间 MoE 层和时间 MoE 层。空间 MoE 负责描述特定图像区域中的不同文本概念,而时间 MoE 处理不同的扩散时间步长。每个块都使用边缘监督交叉注意力学习来进一步提高图像质量。 (b) 显示了 space-MoE 的详细信息。例如,给定提示“天空下有毛茸茸的熊”,每个文本标记及其相应的图像区域(由二进制掩模给出)都通过不同的空间专家进行引导,即每个专家都学习一个区域的特定视觉特征。通过堆叠多个空间 MoE,我们可以轻松学习描述数千个文本概念。
6 月
1 日,Snap 研究院推出最新高性能 Stable Diffusion 模型-SnapFusion,主要是对 UNet 进行优化,还提出一种 CFG-aware 蒸馏损失函数,在 iPhone 14 Pro 上实现 2 秒出图(512x512),且比 SD-v1.5 取得更好的 CLIP score。
这也是目前在移动端出图最快的
同日,Wuerstchen被提出,其团队开发了一种潜在扩散技术,这种高度压缩的图像表示提供了更详细的指导,这显着降低了实现最先进结果的计算要求,能够以两倍以上的速度执行推理。
19 日,美图发布基于扩散模型的视觉大模型 MiracleVision,运用零样本学习算法,利用类别的高维语义特征代替样本的低维特征,使得训练出来的模型具有迁移性。
7 月
12 日,Kandinsky 2.2 对其前身 Kandinsky 2.1 进行了重大改进,引入了新的、更强大的图像编码器 - CLIP-ViT-G 和 ControlNet 支持。
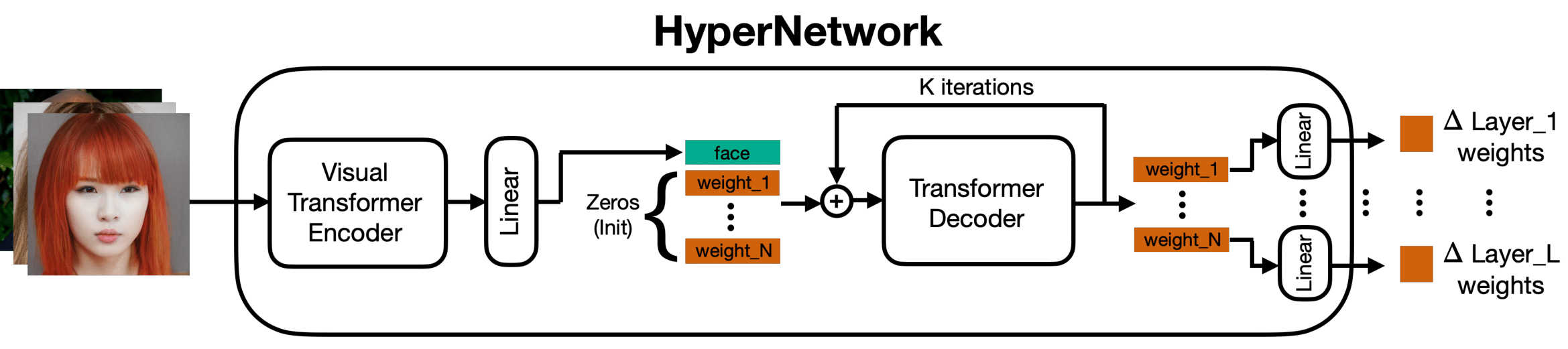
在去年,谷歌提出了 DreamBooth,是我们微调 SD 的方法之一,时隔 8 月,谷歌在 7 月 13 日又提出了HyperDreamBooth,但开源工作还得靠大家。它能通过超网络和快速微调实现高效的个性化生成,减小模型大小并提高生成速度。
14 日,Meta 在官网公布了CM3leon,首个基于 Transformer 的多模态自回归模型。我们前面看到更改 Transformer 的扩散模型,而这里是自回归。CM3leon 采用的是完全不同的方法,它利用注意力机制来权衡输入数据(无论是文本还是图像)的相关性。Transformer 结构的好处是什么?并行啊,而且训练的计算量还比此前基于 Transformer 的方法少了五倍。

从这张图可以看见,CM3leon 赢麻了。要是开源就更好了!🥹🥹🥹🥹
CM3leon 还使用 SFT 训练,SFT 已在 ChatGPT 训练中得到认证。果然取经还得去 NLP。
27 日,Stability AI 正式公布最新的开源绘图模型——SDXL1.0,其实最早在 4 月就发布,6 月推出 0.9 的研究版本。Stable Diffusion XL 已经超越了先前发布的各种版本的 Stable Diffusion,并且与当前未开源的文生图 SOTA 模型(如 midjorney)具有不相上下的效果。
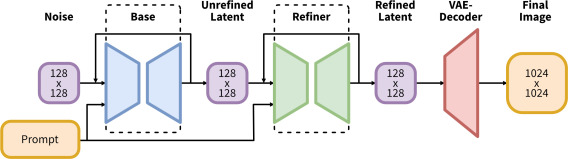
Stable Diffusion XL是一个二阶段的级联扩散模型,包括 Base 模型和 Refiner 模型。其中 Base 模型就是原来的 SD,而原来的模型有时会产生局部质量较低的样本,因此接入了 Refiner 模型,在同一潜在空间中训练一个单独的 LDM,该 LDM 专门用于高质量、高分辨率数据并采用 SDEdit 在 Base 模型的样本上引入的噪声去噪过程。
SDXL 使用了更大的 backbone,参数量大约为之前版本的 SD 的 3 倍。
9 月
9 月,DALL-E 3基于 DALL-E 2 和 ChatGPT 的文生图模型,同时发布的还有 GPT-4 Turbo,现在大家用的 GPT4 多模态功能中的绘图功能,没错,用的就是 DALL-E 3。
在前面我们说过,DALL-E 3 模型架构基于扩散模型,它同时还继承 transformer 架构,使用 T5 XXL 文本编码器来处理输入文本。
此外,DALL-E 3 论文还提出一个定制的图像字幕生成器(image captioner)来为训练数据集生成改进的字幕,这显着增强了模型的提示跟踪能力。这有什么用呢?你可以想想,有时候你的提示词,真的生成了你想要的图片了吗?这个工作就是做了这方面的探索。
10 月
6 日,站在 OpenAI 的肩膀上,清华大学交叉信息研究院的研究者提出Latent Consistency Models(潜在一致性模型),采用一致性蒸馏 Latent Consistency Distillation(LCD)的方法,在 SD 模型的基础上蒸馏加速后的基础模型或 LoRA 模型。
- LCD 在潜在空间中进行,利用自动编码器将高维图像数据转换为低维潜在向量,并通过解码重构图像来降低计算负担并合成高分辨率图像。
- LCM 集成了无分类器引导到其过程中,采用单阶段引导蒸馏方法,并使用跳步技术加速收敛。
- LCF 是一种微调方法,用于在定制化数据集上高效进行推断。
- 此外,LCM 中的采样算法与传统多步采样不同,它直接预测增强轨迹的起点,从而实现单步样本生成,以提高图像质量。
10 日,Adobe 的 Firefly2(萤火虫 2 号)出场,提升了图像质量,引入矢量图生成功能。
23 日,苹果提出了俄罗斯套娃式扩散模型(Matryoshka Diffusion Models,MDM),一种用于高分辨率图像和视频合成的端到端框架。MDM 的主要创新之处在于其能够在多个分辨率上联合去噪输入,并采用了一种嵌套式的 UNet 架构。MDM 通过在扩展空间中引入多分辨率扩散过程,在此过程中学习单一扩散过程与层级结构,使得 MDM 能够同时生成多种分辨率的图像。MDM 还采用了正常去噪目标在多个分辨率上进行联合训练,并使用渐进式训练技术,逐步将更高分辨率加入训练目标中,从而加快了整体收敛速度。此外,MDM 的 NestedUNet 架构将所有分辨率的潜在变量组合在一个去噪函数中,形成一个嵌套结构,共享多尺度计算,简化了高分辨率生成的学习过程。
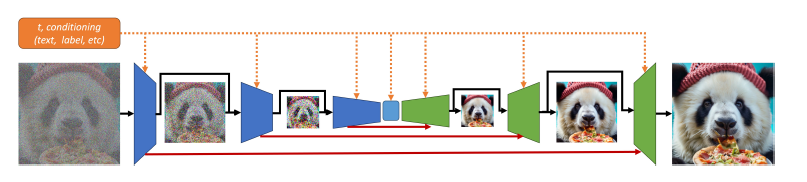
11 月
相对上面的 LCM 代码开源,2 日,谷歌提出了UFOGen,一种能极速采样的扩散模型变种,UFOGen 采用混合方法,将扩散模型与 GAN 相结合。利用新的 diffusion-GAN 和预训练扩散模型的初始化,UFOGen 可以在单步中根据文本描述生成高质量图像。
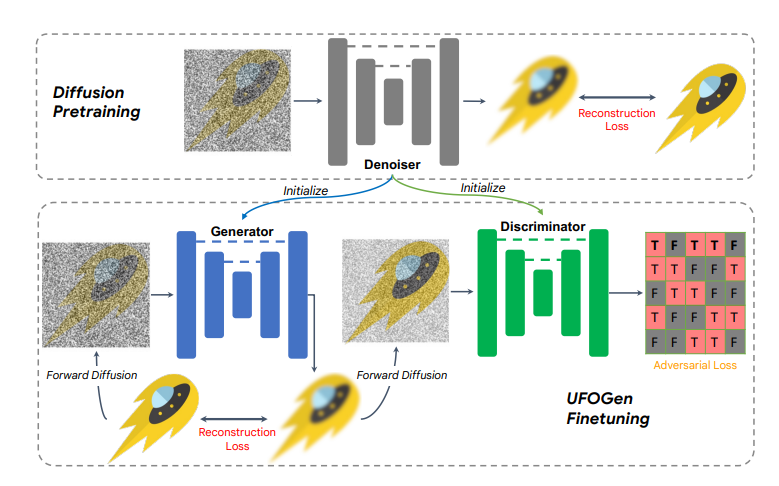
于是就有目前提升扩散模型的生成速度的 5 条路:
- 设计更加高效的数值计算方法硬解 ODE(常微分方程),比如清华朱军团队提出 DPM-Solver++
- 利用知识蒸馏 ODE,比如 LCM
- 量化
- 换结构
- 扩散与 GAN 结合
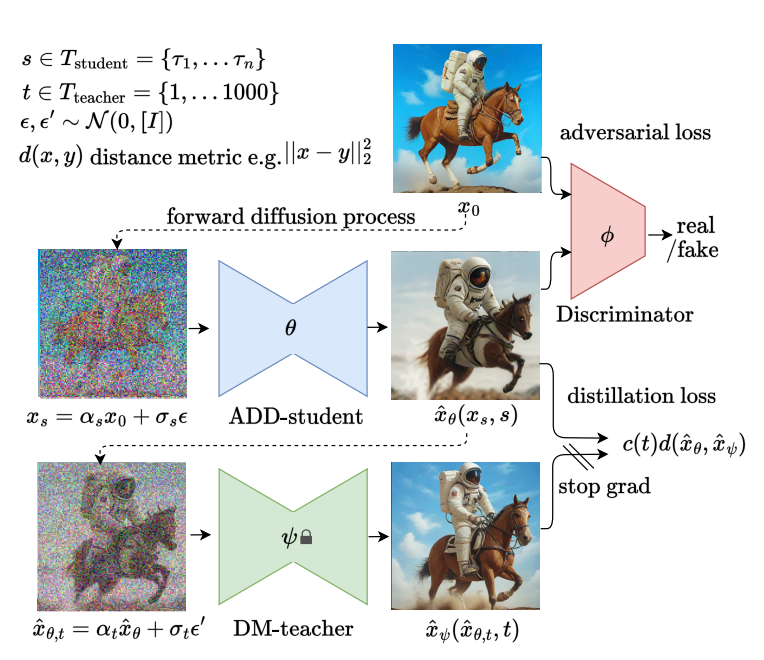
28 日,Stability AI 在官网发布了开源文生图模型SDXL Turbo,可以做到文本生成图片实时响应,比 LCM 还快。SDXL Turbo 是基于 SDXL 1.0 迭代而成,使用了全新的对抗扩散蒸馏技术(Adversaral Diffusion Distillatio,ADD),所需图像的生成步骤从 50 步减少到 1 步,并且不会损坏图片的质量。
ADD 采用两种类型的蒸馏损失:首先是对抗性损失(adversarial loss),其中鉴别器的任务是区分生成的图像和真实图像;其次是传统的蒸馏损失,它将学生模型的输出与教师模型的输出对齐
12 月
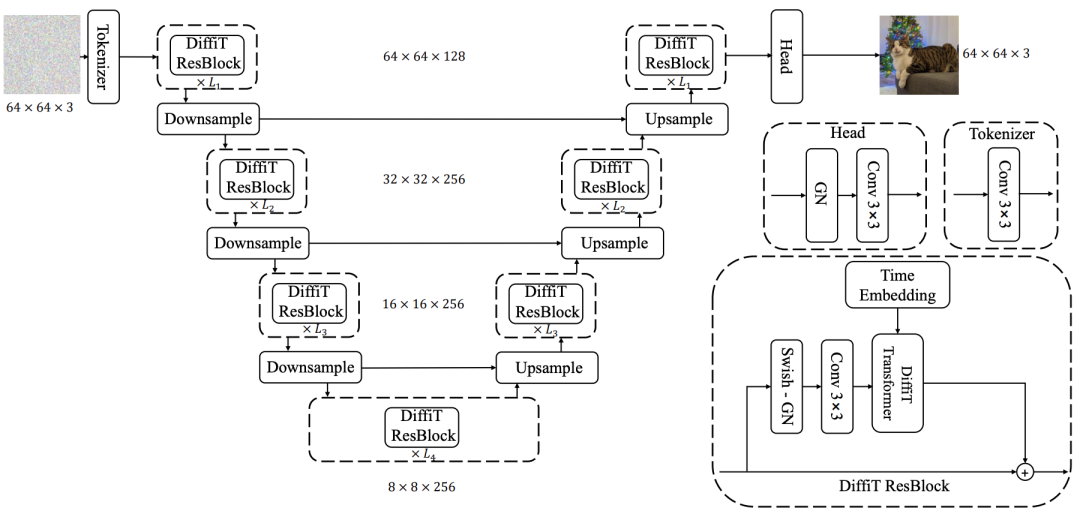
4 日,英伟达提出用于图像生成的扩散 ViT 架构DiffiT,本文提出一种新模型,称为扩散视觉 transformer (DiffiT),由一个具有 U 形编码器和解码器的混合分层架构组成。本文提出一种新的依赖时间的自注意力模块,允许注意力层以有效的方式自适应其在去噪过程的不同阶段的行为。 此外,本文还提出了 LatentDiffiT,由 transformer 模型和所提出的自注意力层组成,用于高分辨率图像生成。结果表明,DiffiT 在生成高保真图像方面惊人地有效,并在各种类条件和无条件合成任务中实现了最先进的(SOTA)基准。在潜空间中,DiffiT 在 ImageNet256 数据集上取得了新的 SOTA FID 分数 1.73。
又一篇替换成 transformer 的结构的论文
15 日,谷歌发布 Imagen2,图像逼真程度达到新高度。同样也是扩散模型。

21 日,Midjorney V6 出世,图像质量更好,语言理解能力更强。
思考与总结
2023 的文生图很卷,我在上面尽可能地列举了很多架构,如果不是创新就没有出现在上面。
当然大家如果还看见其它文生图方面的创新在本文并没有列出,可以在底下回复,我将会进行相应的补充。
总得来说,在算法层面,现在对文生图的研究多在于扩散模型推理优化和扩散模型结构替换。要么从底层重写算子,要么通过数学等方面优化模型的调度器,Unet,softmax 等。在结构替换上,越来越多的学者开始替换 Une。说不定在 24 年之后,Stability AI 发布新 SD 版本之时,都直接宣布了 Unet 不存在了。
这仅仅是算法层面,在应用层面,以主流的扩散模型为例,如果你去搜索相关扩散模型论文,你会发现围绕扩散模型的应用真的很多很多。😂
目前,文生图还是有许多技术难点等待攻破,实际上终究难逃 3 个要素:算法,算力,数据集。
算法的提出就是为了图片生成速度更快,图片的质量更高,这是肯定的,但你看,现在的图片都是固定尺寸产生的,如果我想生成任意尺寸的呢?VAE 如何用 GPU 加速呢?等等...思维不够发散。
再说数据集,大家肯定都知道前段时间有 2 个新闻,1 是字节被爆用了 ChatGPT 训练,2 是谷歌 Gemini 被爆中文语料用文心一言,数据集永远是不够的,而数据集的开源工作实在是太少了。
最后说说算力,一方面要造更多国内 GPU,CPU,AI 芯片,弥补算力不足的漏洞,另一方面,实际上这也是算法,上面也有工作在做扩散模型的加速工作,在当前大模型大爆发的时代,算力资源尤其缺乏,这往往也是模型落地的一大阻碍。所以,如何让文生图在有限的算力上运行呢?比如在 2080TI 上?比如在内存只有 2GB 的 5,6 年前的老显卡上?可能老的显卡就是无法运行,我希望我们有时候看到的不是又出什么模型,效果多么好,普通显卡能运行吗?而是模型的运行下限又被攻破了,我们可以在更低算力的显卡上跑了!
在当前,AI 创业搞得如火如荼,许多创业公司可基于 Stable Diffusion 基础版本进行进一步调优和个性化数据训练,其实我感觉文生图领域的商业模式有待讨论,因为说到 SD,现在大家只要买个 RTX3090 也能跑,甚至在手机上也能,买卖的群体只有小白以及显卡算力不足的用户,只图个方便,没有其它引用用户的地方。其实说实话,当文生图深入我们的生活时候,这种热度自然而然就淡下去了,最后留下来的公司只有少数,当然你搞个性化数据也没有用,生成的图片终究到用户手上,终有勇士把这些收集起来,重新训练公开出去,所以搞文生图且用 SD 创业的公司存活率我认为不是很高,没有属于自己的核心技术,终究无法有自己的地位。
好了,本文的介绍内容就这么多,如果上面的内容有任何不对,欢迎大家的指出。
参考文献
- AIGC 专题报告:从文生图到文生视频,技术框架与商业化-国海证券
- https://zhuanlan.zhihu.com/p/669353808
- https://zhuanlan.zhihu.com/p/660924126
- https://zhuanlan.zhihu.com/p/646831196
- https://news.adobe.com/news/news-details/2023/Adobe-Releases-Next-Generation-of-Firefly-Models/default.aspx
- https://cloud.google.com/blog/products/ai-machine-learning/imagen-2-on-vertex-ai-is-now-generally-available
- https://www.zhihu.com/column/c_1631303321183805441