熟悉 AI 训练的人大多知道,在 PyTorch 里,通过 pin_memory 可以加速数据加载和 CPU→GPU 的传输。我在面试里也被问过这个问题:“pin_memory 到底干嘛的?为什么会变快?什么时候该用?”
今天就把这块内容系统地梳理一下。实战中 pin_memory 其实主要有两种用法:
- 在
DataLoader里打开pin_memory=True - 手动对张量调用
tensor.pin_memory()
很多坑也恰好就踩在这两种用法上。
内存管理基础
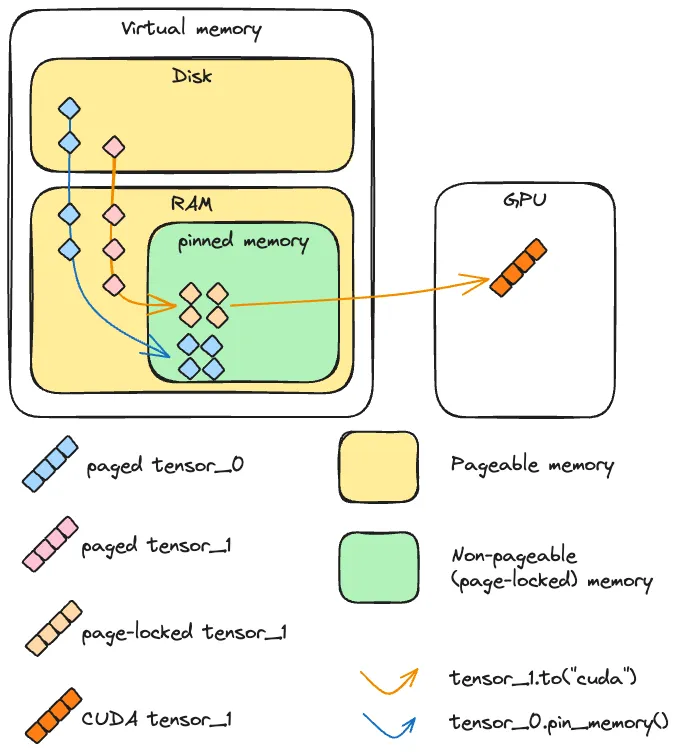
在 CPU 视角下,“内存”其实是虚拟内存 = 物理内存(RAM) + 磁盘交换空间 的抽象:
- 进程看到的是一大片连续的“虚拟地址空间”
- 实际上这些页面(page)可能在 RAM,也可能被换到磁盘上(swap)
这就是所谓的 pageable memory(可分页内存):
操作系统可以随时把某些页从 RAM 换出到磁盘,再在需要时换回来。
它的好处:
- 让你“看起来”有比实际物理内存大得多的可用空间
- 让 OS 自由调度哪些页在内存、哪些在磁盘
坏处:
- 访问一个当前不在 RAM 里的页会触发 page fault,需要从磁盘换入,延迟巨大
- 对于需要稳定带宽和低延迟的数据传输(比如 GPU DMA),这种不确定性是灾难
与之对应的是 pinned / page-locked memory(固定内存 / 页锁定内存):
- 这部分内存不会被换出到磁盘,一直“钉死”在物理内存里
- 访问延迟更可预测
- 但数量有限,而且每次 “pin” 的操作本身就比较昂贵
一句话:pinned memory = OS 承诺“这块内存一直在 RAM,不给你换走”。
CUDA 视角
接下来从 GPU 的角度看一眼:CUDA 是怎么把数据从 CPU 搬到显存里的?
- 如果源数据在 pinned 内存:
GPU 的 DMA 引擎可以直接从这块内存把数据搬到显存,传输路径非常直接。 - 如果源数据在 pageable 内存:
CUDA 不能直接对 pageable 内存做 DMA,因为 OS 随时可能把这块页换走。
实际流程是:- CUDA 驱动在内部申请一块临时 pinned buffer
- 把 pageable 内存的数据 copy 到这个 buffer
- 再从 buffer 通过 DMA 拷贝到 GPU
也就是说,pageable→GPU 实际上是“两次拷贝”:
pageable →(内部 pinned 缓冲区)→ GPU
而 pinned→GPU 是:
pinned → GPU
少了一次拷贝,带宽和延迟自然更好。
所以,
- 直接
pageable_tensor.to('cuda')比pinned_tensor.to('cuda')稍慢 - 因为前者在驱动层偷偷做了一次“隐式 pin + 拷贝”,后者不用。
PyTorch 视角
对张量直接操作
现在从 PyTorch 视角看to()、pin_memory() 和 non_blocking。
to
tensor.to(device):底层一直是异步拷贝
当你写:
y = x.to("cuda")底层用的其实是 cudaMemcpyAsync —— 也就是 异步拷贝。
那为什么感觉它是“同步”的呢?
关键是 PyTorch 在默认情况下帮你做了“拷完就同步”:
non_blocking=False(默认):- 异步提交 CUDA 拷贝后,紧接着做一次 stream 同步;
- 对 CPU 来说,这就是一个阻塞调用。
non_blocking=True:- 只提交拷贝,不立刻同步;
- CPU 线程可以继续向下执行,稍后你自己在合适的地方统一
torch.cuda.synchronize()。
所以重点:
non_blocking=True 不是“让它变成异步”,
而是“别在这一步就等完它”。
pin_memory
PyTorch 提供两种常见方式创建 pinned 张量:
# 普通 pageable 张量
pageable_tensor = torch.randn(1_000_000)
# 直接在 pinned memory 里创建
pinned_tensor = torch.randn(1_000_000, pin_memory=True)
# 或者:从 pageable 复制一份到 pinned
pinned_tensor2 = pageable_tensor.pin_memory()几点要记住:
pin_memory()会复制一份新张量,不是给原张量“打个标签”;- 这个复制过程在你调用的那个线程上是 阻塞的:
- 必须等数据复制到 pinned 内存后,函数才返回。
也就是说:
pin_memory() 本身是一个“挺重”的操作,随手乱用只会拖慢程序。
异步 + pinned 才能真正重叠
要让“传输 + 计算”真正重叠起来,需要同时满足三个条件:
- 源数据在 pinned memory;
- 使用的是非默认流或合适的 stream 设计(对多数训练场景 PyTorch 已帮你处理得差不多);
- GPU 有空闲 DMA 引擎可用。
对我们平常写训练 loop 来说,核心简化版本就是:
DataLoader(pin_memory=True)+.to(device, non_blocking=True)
一些坑
如果是手动操作的话,还要注意下面 3 点。
pin_memory().to()可能比to()还慢
这里做了两件事:
pin_memory():在主线程上分配 pinned + 复制一次数据(阻塞);.to("cuda"):再从 pinned 内存异步拷贝到 GPU。
而如果直接 to():
- CUDA 驱动内部会做一次“隐式 pin + copy”;
- 这套流程是 C++/驱动层高度优化过的,拷贝、缓存、重用策略都比你 Python 层
pin_memory()要聪明。
所以只用一次的张量,写成 x.pin_memory().to() 多半是在浪费时间。
只有当你反复用同一块 pinned 内存时,这个开销才值得摊平。
- 一般用
tensor.to(device, non_blocking=True)就够爽
在多数训练场景中,一种很好的“默认姿势”是:
for x, y in loader: # loader 里 pin_memory=True
x = x.to(device, non_blocking=True)
y = y.to(device, non_blocking=True)
...它的好处是:
- 拷贝本来就是异步的;
non_blocking=True让 CPU 可以“先发起多个拷贝,再统一等待”,减少无谓的同步;- 如果
x、y本身来自 pinned 内存(比如 DataLoader 帮你 pin 了),传输可以更快、更平滑。
- CPU→CUDA 可以 non_blocking,CUDA→CPU 小心翻车
两个看起来对称的代码段:
# 情况 A:CPU -> CUDA
cpu_tensor = ...
cuda_tensor = cpu_tensor.to("cuda", non_blocking=True)
result = cuda_tensor.mean() # 在 GPU 上算,通常没问题
# 情况 B:CUDA -> CPU
cuda_tensor = ...
cpu_tensor = cuda_tensor.to("cpu", non_blocking=True)
result = cpu_tensor.mean() # 在 CPU 上算,可能错误为什么 A 正常、B 却可能出问题?
- 情况 A:
.to("cuda", non_blocking=True)提交 H2D 拷贝;.mean()这个 kernel 在同一条 CUDA stream 上排队;- CUDA 保证同一 stream 上“先拷贝,再计算”,所以数据是完整的。
- 情况 B:
.to("cpu", non_blocking=True)提交 D2H 拷贝后立刻返回一个 CPU 张量;- 此时这块 CPU 内存可能还在被填充;
.mean()是 CPU 运算,PyTorch 不会自动给你torch.cuda.synchronize();- 于是 CPU 直接读了“半成品数据”,结果当然乱。
正确写法应该是:
cuda_tensor = ...
cpu_tensor = cuda_tensor.to("cpu", non_blocking=True)
torch.cuda.synchronize() # 等拷贝结束
result = cpu_tensor.mean()所以可以记一条小口诀:
CPU→CUDA 的
non_blocking=True一般安全;
CUDA→CPU 的non_blocking=True必须自己同步。
DataLoader 的 pin_memory
“既然 pin_memory() 本身是阻塞操作,那在 DataLoader 里打开 pin_memory=True 为什么还会加速?我们也没在那一步用 non_blocking 啊?”
这里有两个关键点。
- pin 的阻塞发生在 DataLoader 的 worker 里
当你这样写:
train_loader = DataLoader(
train_dataset,
batch_size=64,
shuffle=True,
num_workers=8,
pin_memory=True,
)num_workers > 0时,DataLoader 会起多个子进程/线程:- 负责读数据、做 transform、collate、pin 内存。
- 这些阻塞操作,全都在 worker 里进行,不在你的训练主线程上。
换句话说:
当你的训练 loop 写 for data, target in train_loader 时,
worker 们已经在后台帮你把这个 batch pin 好了。
- 训练主线程只做:拿 pinned batch → 异步拷贝到 GPU
训练 loop 大概是这样:
for data, target in train_loader:
data = data.to(device, non_blocking=True)
target = target.to(device, non_blocking=True)
output = model(data)
loss = criterion(output, target)
loss.backward()
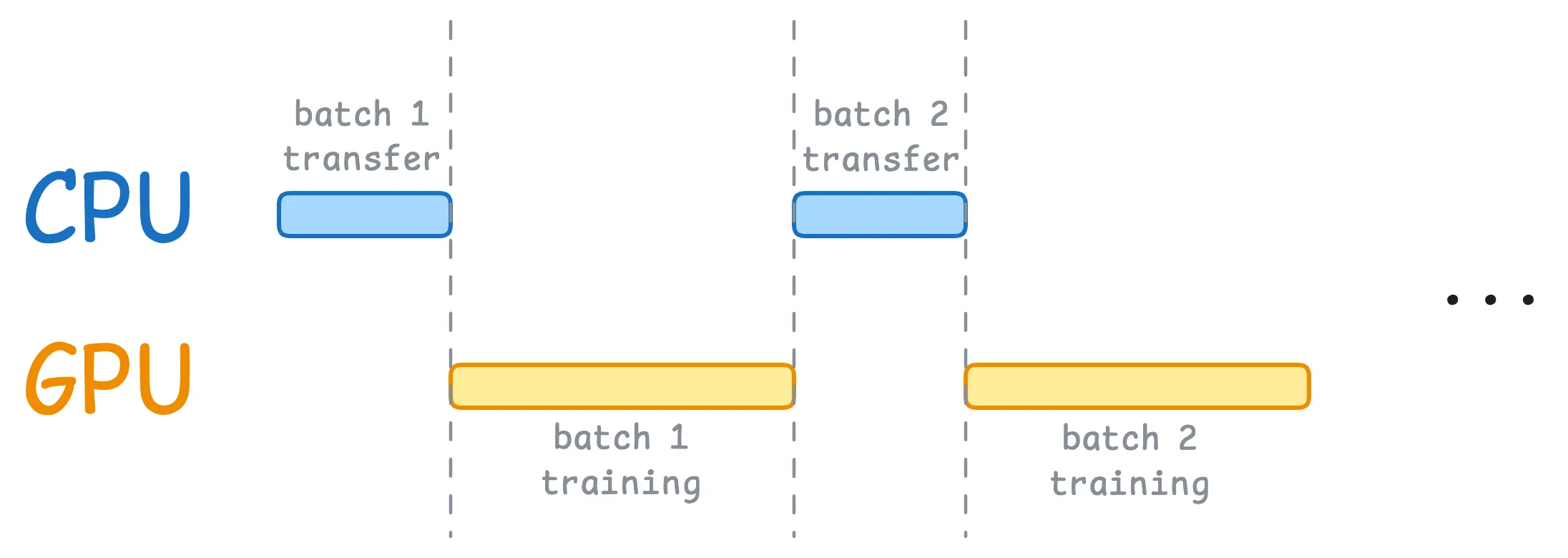
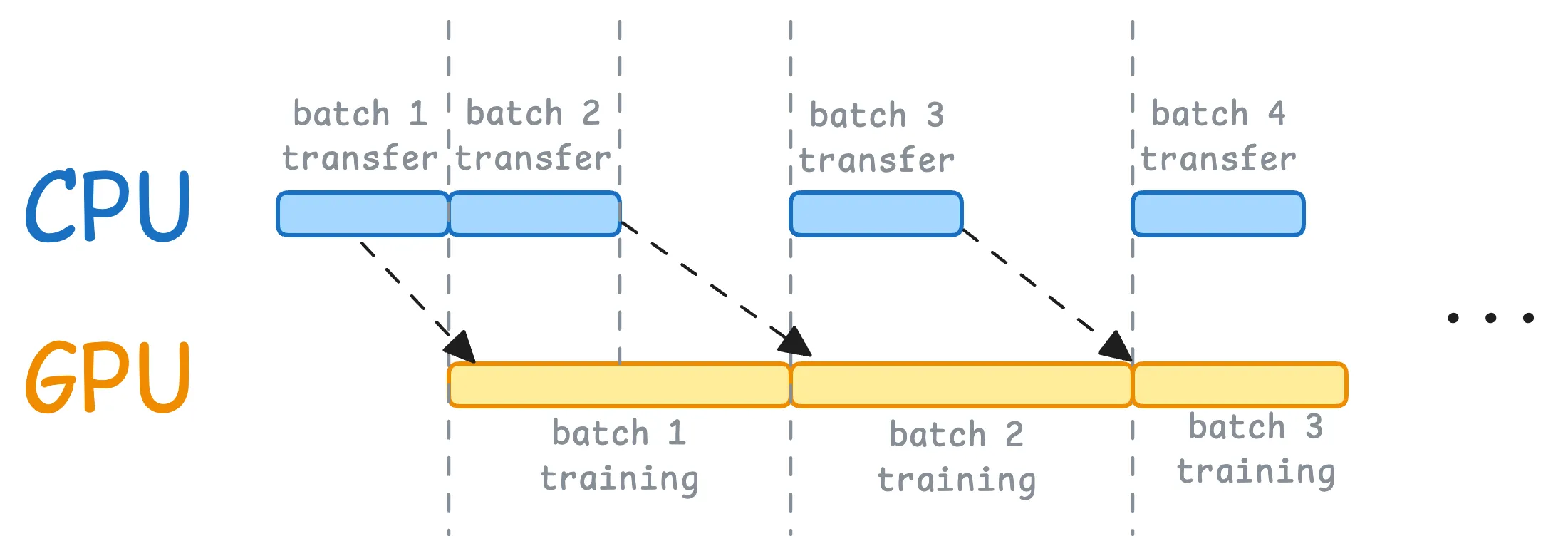
optimizer.step()时间轴上是:
- GPU 正在训练上一批 batch i;
- DataLoader worker 正在后台准备并 pin 好 batch i+1;
- 当前这批算完后,
data.to(device, non_blocking=True)马上把 batch i+1 往 GPU 上推; - GPU 几乎无缝衔接下一批,不再干等数据。
默认:
使用之后:
实战建议
- 这种情况,建议开
pin_memory=True
大致有这么几类:
- 大规模 GPU 训练
- 大 batch、高分辨率图像/视频、音频等,高吞吐场景;
- 多 GPU / 分布式训练
- 多张卡同时吃数据,对数据管线延迟非常敏感;
- 低延迟或实时推理
- 每一毫秒都要抠的时候,
pin_memory + non_blocking能省下不少时间。
- 每一毫秒都要抠的时候,
搭配方式几乎统一是:
loader = DataLoader(..., pin_memory=True, num_workers=合理值)
for x, y in loader:
x = x.to(device, non_blocking=True)
y = y.to(device, non_blocking=True)
...- 这些情况,可以不用折腾 pin_memory
- 只在 CPU 上训练或推理
- 开了也没有任何收益,只是多占 RAM;
- 小数据集/轻量任务
- 数据一下子全塞进 GPU,不存在“GPU 等数据”的瓶颈;
- 机器内存本身就不多(比如 8G)
- pinned 内存不能被换出,如果你 pin 得太多,系统会非常难受。
- 手动
pin_memory()适合的场景
- 实时推理,反复复用固定形状的输入缓冲区;
- 高频 GPU→CPU 回传,自己维护少量 pinned buffer,通过
.copy_()往里写; - 自己写异步 pipeline,希望精细控制哪一步 pin、哪一步拷。
不适合的用法:
for data, target in loader:
data = data.pin_memory() # ❌ 每个 batch 再 pin,一般只会更慢
data = data.to(device, non_blocking=True)这基本就属于“在训练主线程上多复制了一遍大 tensor”,收益极低。
总结
pin_memory = 把张量钉死在 RAM 里,让 GPU 传输更顺畅,但他其实是个阻塞操作。
真正好用的姿势是:让 DataLoader 在后台帮你 pin,
然后在训练 loop 里用 .to(device, non_blocking=True) 把传输和计算串成流水线。
少在主线程里乱 pin_memory(),GPU→CPU 的非阻塞传输记得自己同步。